
在一個充滿活力的校園里,安娜老師是深受學生喜愛的教師。但是這幾年她發現,在這個信息爆炸的時代,擁有良好的摘要能力變得尤為重要。然而,許多學生在總結時往往抓不住重點,或者表達不夠清晰流暢。於是安娜老師開始加強練習學生摘要總結的能力。但每當周末來臨,她的笑容就會變得有些勉強——因為那意味著又有一堆學生們的摘要練習等著她去批改。
今天要介紹的比賽,是去年2023年7月舉辦的、為期也是3個月左右的 kaggle 競賽,CommonLit - Evaluate Student Summaries,一樣也是由 The Learning Agency Lab 發起的比賽。不過,前幾天介紹的是「議論文」相關的自動打分系統,這次的是摘要寫作的評分,相比前一個只要針對學生寫的文章內容獨立評分即可;這次還要參考學生摘要的對象,也就是原文,再去比對這個摘要內容是否有摘述到原文的重點與精髓,再去評價行文的流暢度邏輯性等等。
不得不說,安娜老師真的是很會善用科技的力量來減輕自己工作的負荷,實乃我輩打工人的楷模xdd
下面是本賽題主辦方提供的訓練與測試資料簡介:
summaries_train.csv 的前三筆資料截圖如下: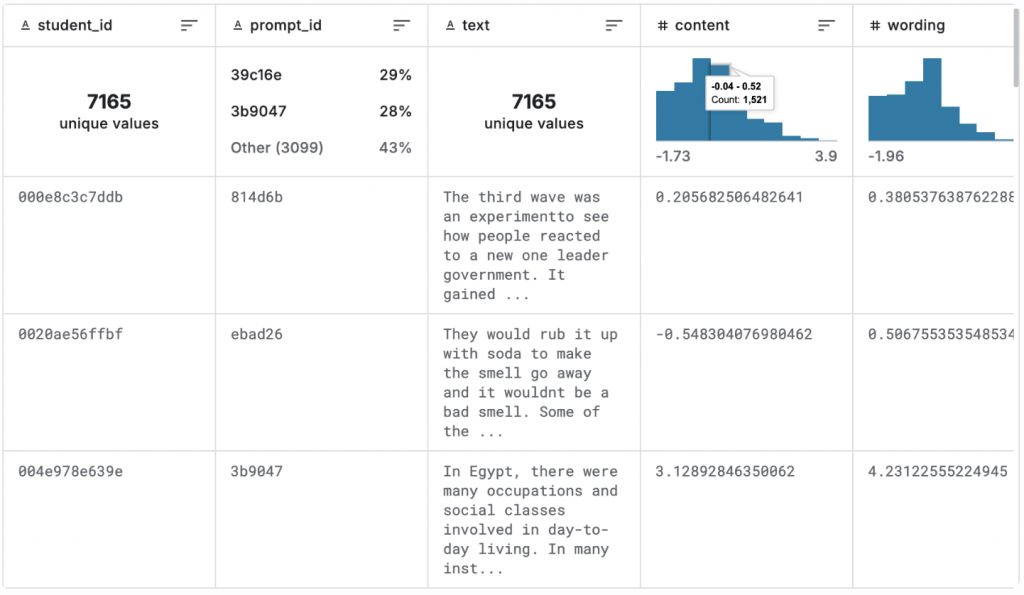
特別說明一下,這邊的 prompt 指的是題目的意思,也就是學生在寫摘要前要參考的題幹。這個題幹會包含要摘要的對象也就是原文的標題、原文的內容、以及要從哪些面向摘要,或說摘要的方向要求,也可以說是學生被要求要回答的具體問題。
summaries_test.csv - 測試集中的摘要。包含上述所有字段,除了content和wording score。
prompts_train.csv - 只包含 4 個 training set 所使用到的題幹說明文件,包含下面幾個 column:

值得注意的是,trainset/testset/hidden testset之間不共享任何prompt(題目)。
整個 dataset(包含所有訓練和測試資料),大約有24,000篇由三年級到十二年級學生撰寫的摘要,涵蓋了多種主題和類型的文章。其中訓練資料佔了 7165筆,測試資料佔了大約 17000 筆。
值得注意的是,我們透過觀察summaries_train.csv的 prompt_id,發現只有4個不同的 prompt_id,prompt_train.csv也只有4筆資料,分別說明這四個題幹的內容與要求)。
但是!
「完整的測試集有大量的題目(prompt)」 這句話很重要呦(根據可靠消息,大概來自 122 個 prompts)!
這代表我們無法取得的測試資料其實是非常多元的、來自不同題目的要求,並且還和訓練資料沒有任何一題重疊,所以我們的 model 要如何從訓練資料 transfer 到測試資料會是很大的挑戰。
由於這次比賽有兩個要預測的目標:content score(摘要的整體內如分數,包含是否有完整摘述原文重點),以及 wording score(摘要的措辭分數),因此本次比賽採用:
MCRMSE,即均方根誤差的列均值(Mean Columnwise Root Mean Squared Error):
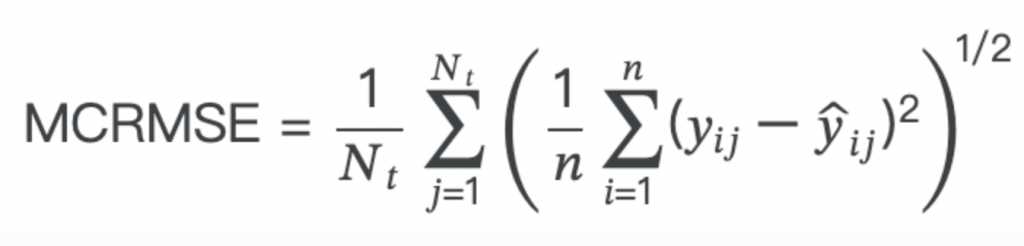
其中 (N_t) 是評分的真實目標列的數量,(y) 和 (\hat{y}) 分別是實際值和預測值。
這個指標評估的是模型預測值與實際值之間的均方根誤差,但進行了平均處理以考慮多個目標列。首先計算每個目標列的均方誤差,然後對每列的均方誤差求平方根,最後對所有列的結果取平均。這樣能夠提供一個整體的衡量模型在多個目標上預測性能的指標。
另外本次比賽和前幾天介紹的比賽一樣,都是 code competition,也就是無法拿到完整的 test data 的 input,只能上傳 code 去操作放在系統後台的 test data。這種比賽還需要額外注意他的運算資源限制:
我們之後要評估每個sample平均的字數長度、inference的時間,來決定我們到底可以ensemble幾個模型,才不會在測試的時候超時。
也許你會好奇,明明這個比賽相比前幾天介紹的Automated Essay Scoring 2.0早發布,為什麼不先介紹這個比賽呢?
因為這個比賽的許多參賽者有使用 LLM 擴增資料等技巧,我認為相比前一個比賽來說會更複雜一些,所以挪到第六天再來介紹~
目前為止,你已經了解比賽的目標、資料的數量及其 input 與 output 的格式了,還有評分所使用的 metric 了。
❓❓可以暫停一下,思考看看,如果你是參賽者,你會如何設計你的第一個解題方案呢?你的第一步是什麼❓❓
在開始前,還是再次解釋一下之後會時常出現的 "CV" 和 "LB" 這兩個詞到底是什麼意思? 我第一次看 Kaggle 討論區時,常常看人家在討論他們但搞不懂在指什麼。
CV分數指的是我們在訓練集上通過交叉驗證(Cross-Validation)得到的(MCRMSE)分數。本次比賽的一個重要點是,無論是 hidden testset還是public test set都包含了我們的模型從未見過的prompt。因此,我們需要采用一種交叉驗證方法,確保模型在驗證時面對的是之前未曾接觸過的prompt。之前提過的“GroupKFold”交叉驗證就是一個解決方案,在每次折疊中,你將一個特定“prompt”的數據留作驗證集,其余數據用作訓練集。
LB分數是指我們在Leadernoard所獲得的public score。由於這個分數僅基於實際測試數據的13%進行評估,而private score則使用剩下的87%,所以我們不應該過度優化LB分數以追求在排行榜上的好位置。相反,我們應該努力使你的交叉驗證(CV)分數成為排行榜分數的良好指標,並盡量優化CV分數,縮小 CV 和 LB 的差距。
(以上說明改寫自1)
也許在看過前面幾天我們介紹過的做法後,你會想,不管了,直接 deberta-v3 large 拿過來,繼續爆 train 一波再說。
但是這次你的 input 要是什麼呢?之前只有 essay 的 context 可以用,這次除了有學生的 summary text,還有 prmpt 的相關資訊,如:promt_title, prompt_question, prompt_text等等,你要怎麼結合?全部當作input concatenate起來丟進去嗎?還是只需要其中某部分即可呢?
如果這些問題會讓你開始覺得有點手足無措、無法決定的話,EDA(Exploratory Data Analysis)作為第一步是個絕妙的好辦法!畢竟 Data Science 最重要的就是"理解我們手中的 data",在過程中享受發掘(discovery)和學習(learning)的樂趣。
為了讓自己和 data 混熟,我們藉由下面幾個問題開始探索數據(相關問題參考自 1,code主要參考討論區無私的分享2)
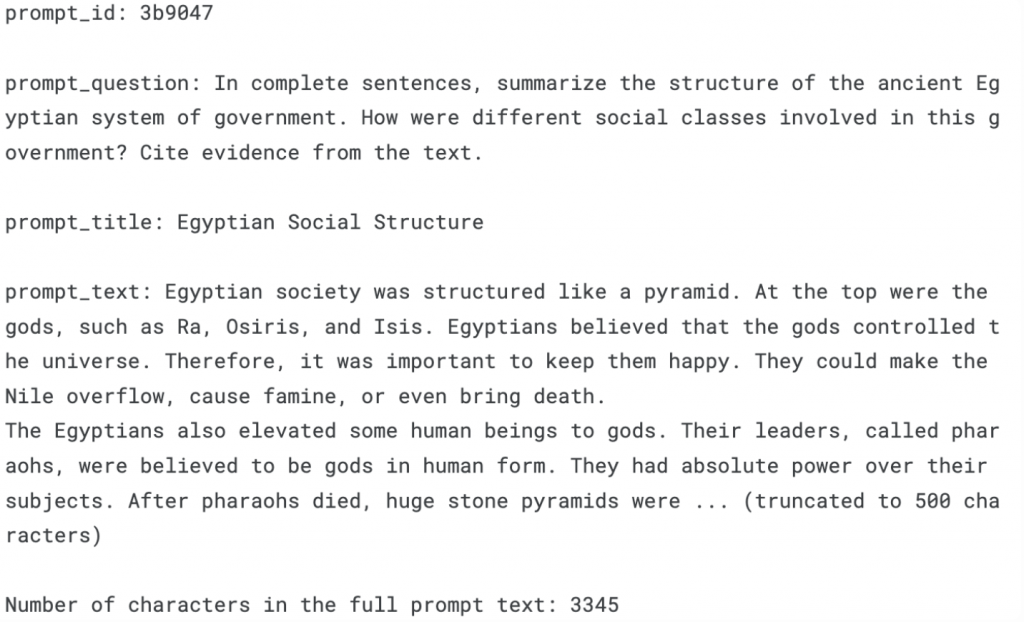
*** 🤔 How do a prompt title, prompt text, prompt question and corresponding student answer look like?**
print(f"prompt_id: {prompts.loc[1]['prompt_id']}\n")
print(f"prompt_question: {prompts.loc[1]['prompt_question']}\n")
print(f"prompt_title: {prompts.loc[1]['prompt_title']}\n")
print(f"prompt_text: {prompts.loc[1]['prompt_text'][:500]}... (truncated to 500 characters)\n")
print(f"Number of characters in the full prompt text: {len(prompts.loc[1]['prompt_text'])}")
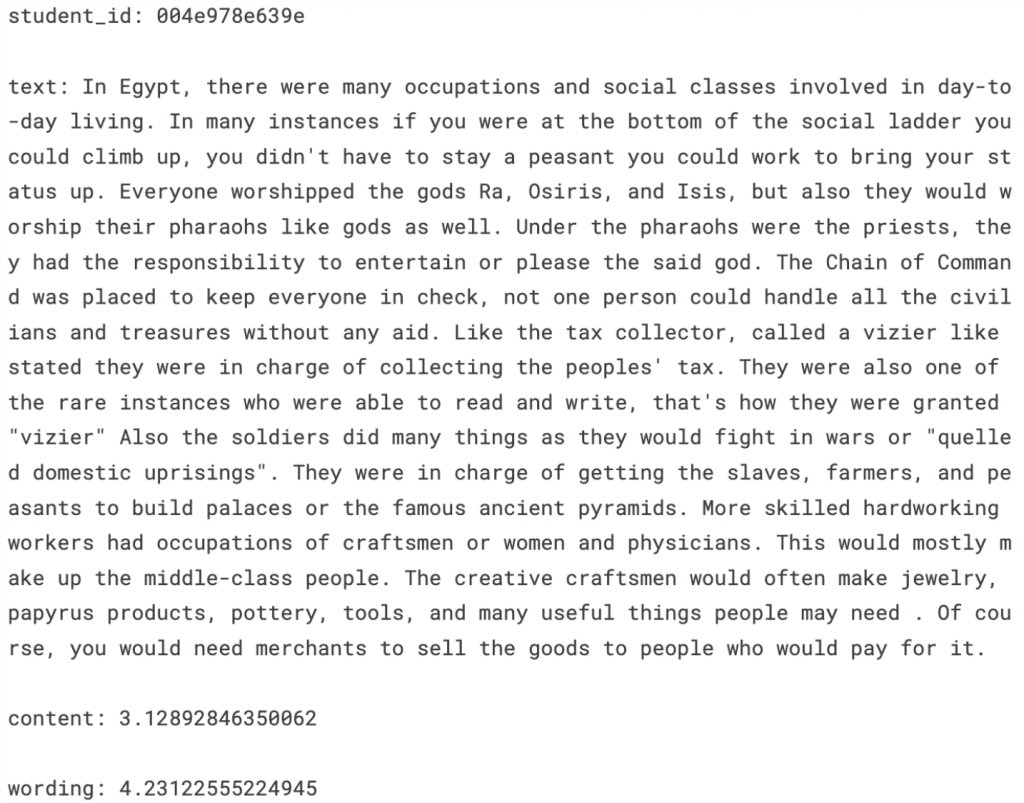
# Example summary
print(f"student_id: {summaries.loc[2]['student_id']}\n")
print(f"text: {summaries.loc[2]['text']}\n")
print(f"content: {summaries.loc[2]['content']}\n")
print(f"wording: {summaries.loc[2]['wording']}")
*** 🤔 How many prompts are in the training data?**
這個前面就提過了,只有 4 個 prompts 出現在 training data。
那 training data 中各有幾成的 data 屬於這些 prompt 呢?
# Frequency comparison of prompts in the training summaries data
labels = summaries['prompt_id'].value_counts().index
sizes = summaries['prompt_id'].value_counts().values
plt.pie(sizes, labels = labels, autopct = '%1.1f%%')
center_circle = plt.Circle((0,0), 0.3, color = 'white')
p = plt.gcf()
p.gca().add_artist(center_circle)
plt.show()
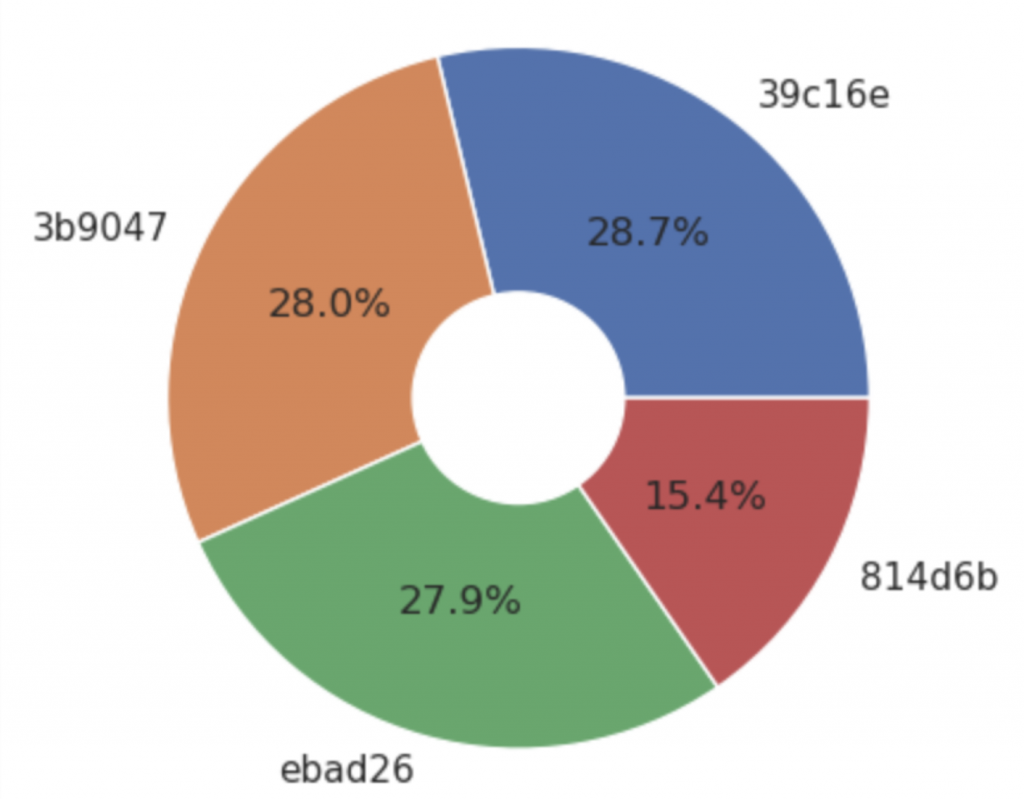
分佈的還算平均,其中的大頭是 39c16e 這個 prompt 是關於 "On Tragedy" 的,共有 28.7% 的 training data 來自這個 prompt。
接下來我們把 prompt 和 training data 合併在一起,方便之後的分析:
merged = pd.merge(prompts, summaries, how = 'inner', on = 'prompt_id')
merged.head()
來複習一下相關係數:
什麽是相關係數?
相關係數是一個統計指標,用來衡量兩個變量之間的線性關系強度和方向。最常用的相關系數是皮爾遜相關係數,它的值範圍從 -1 到 +1。
計算方法
皮爾森相關係數的計算公式為:
r = (Σ(xi - x̄)(yi - ȳ)) / (√(Σ(xi - x̄)² * Σ(yi - ȳ)²))
其中:
xi 和 yi 是兩個變量的觀測值。x̄ 和 ȳ 是這些觀測值的平均數。
此公式實際上測量的是,兩個變量的偏離其各自均值的程度的乘積的平均值。分母是這些偏差的標準差的乘積,這確保了相關係數被標準化,使其在 -1 到 +1 的範圍內。
分數代表的意義
+1 的相關係數表示一個完美的正相關,即一個變量的增加總是與另一個變量的增加相對應。
-1 的相關係數表示一個完美的負相關,即一個變量的增加總是與另一個變量的減少相對應。
0 的相關係數表示兩個變量之間沒有線性關係。
相關係數的絕對值越大,表示兩個變量之間的線性關係越強。
例如:
如果 r = 0.8 或 r = -0.8,這表明兩個變量之間存在較強的正向或負向關係。
如果 r = 0.2 或 r = -0.2,則表示兩個變量之間的關係較弱。
其他分數意義的參考:(reference to 3)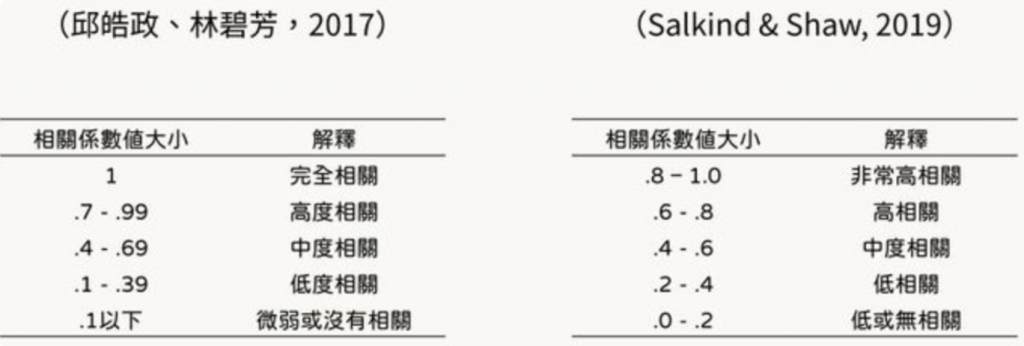
下面的 code 首先會畫出 content score 的數量分佈,以及 wording sccore 的數量分佈。因為這兩個數值都是連續的,為了畫成直方圖的方式呈現,會用 math.floor(2 * (len(train)**(1/3))) + 1 的方式分 bin 來呈現。(其實這邊也可以用 density plot 來呈現)
# Distributions of the target variables and their relationship (training set)
fig, ax = plt.subplots(1, 3, figsize = (15, 5))
c, w, num_bin = train['content'], train['wording'], math.floor(2 * (len(train)**(1/3))) + 1
ax[0].hist(c, bins = num_bin), ax[1].hist(w, bins = num_bin), ax[2].scatter(c, w, marker = '.')
ax[0].set_xlabel("Content"), ax[1].set_xlabel("Wording"), ax[2].set_xlabel("Content")
ax[0].set_ylabel("Count"), ax[1].set_ylabel("Count"), ax[2].set_ylabel("Wording")
t0 = f"Mean: {c.mean():.2f}, SD: {c.std():.2f}, Skew: {c.skew():.2f}, Kurt: {c.kurt():.2f}"
t1 = f"Mean: {w.mean():.2f}, SD: {w.std():.2f}, Skew: {w.skew():.2f}, Kurt: {w.kurt():.2f}"
t2 = f"Correlation Coefficient: {c.corr(w):.2f}"
ax[0].set_title(t0), ax[1].set_title(t1), ax[2].set_title(t2)
plt.tight_layout()
plt.show()
🔎 Findings: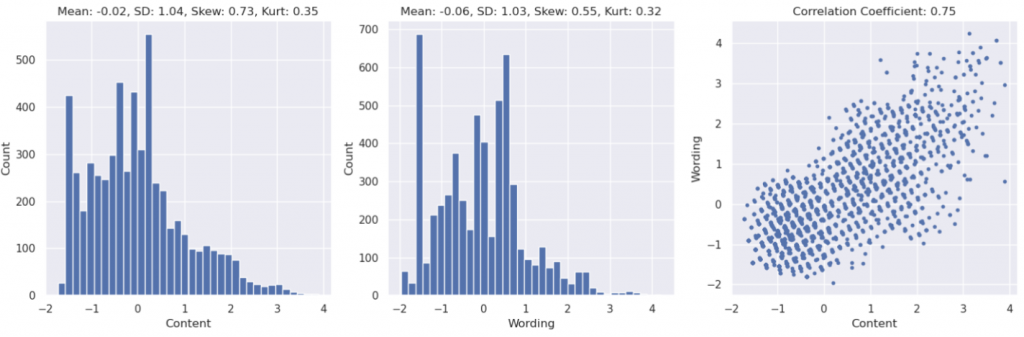
從第三張圖可以看出,Wording 和 Content score 的相關係數有到 0.75,算是高度相關,初步驗證我們的假設。但這個特性我們該怎麼用,還沒有想法。
另外,word score 和 content score 的平均分在 -0.02, -0.06 ,中間偏低分。
另外我們可以執行:
df['content'].nunique(), df['wording'].nunique(), len(df[['content','wording']].drop_duplicates())
結果是(1134, 1134, 1134),代表總共只有 1134 筆完全不同的 content score,以及完全不同的 wording score,並且如果某兩筆資料的 content 分數是相同的,那 wording 分數也一定會相同。
這說明 wording 和 content score 確實具有某種正相關性,但很難當作一個 feature,因為這種特性並不是連續的。
這個...好像不一定吧,想起小時候寫的作文....:(圖片來源:4)
來確認一下吧!
定義這個通用function,可以把要觀察的 feature 統計好之後,存成 list 當成 x 傳入,再傳入這個 feature 的名稱給 name:
def feature_plots(x, name):
fig, ax = plt.subplots(1, 3, figsize = (15, 5))
c, w, num_bin = train['content'], train['wording'], math.floor(2 * (len(x)**(1/3))) + 1
ax[0].hist(x, bins = num_bin)
ax[1].scatter(x, c, marker = '.'), ax[2].scatter(x, w, marker = '.')
ax[0].set_xlabel(name), ax[1].set_xlabel(name), ax[2].set_xlabel(name)
ax[0].set_ylabel("Count"), ax[1].set_ylabel("Content"), ax[2].set_ylabel("Wording")
t0 = f"Mean: {x.mean():.2f}, SD: {x.std():.2f}, Skew: {x.skew():.2f}, Kurt: {x.kurt():.2f}"
t1 = f"Correlation Coefficient: {x.corr(c):.2f}"
t2 = f"Correlation Coefficient: {x.corr(w):.2f}"
ax[0].set_title(t0), ax[1].set_title(t1), ax[2].set_title(t2)
plt.tight_layout()
plt.show()
開始畫:
# Number of characters in summary texts
num_char_train = train['text'].str.len()
feature_plots(x = num_char_train, name = "Number of characters")
🔎 Findings: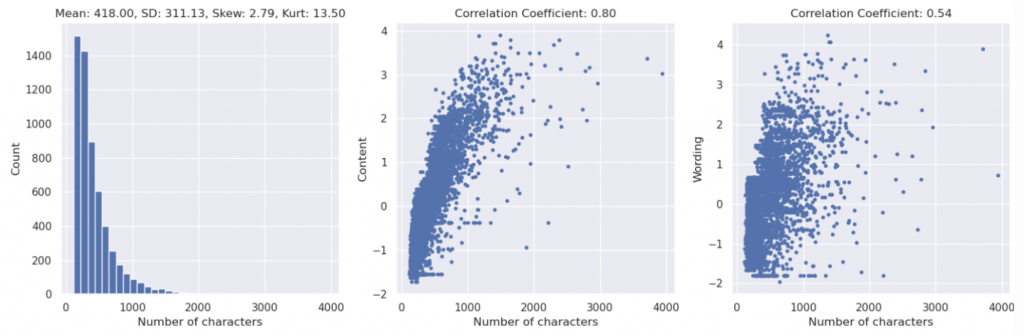
字數和 content score 的相關係數有到 0.8,但是 wording score 的相關係數卻只有 0.54。可能的解釋是,拿高分的摘要,字數可能都不能太少;但有一些充字數的廢文卻在 wording score 上被狠狠地懲罰,拿了低分。
❓❓ 除了字數,我們還能找出什麼 feature 可能和 content / words score 相關呢? ❓❓
英文的 "stop words" 指的是在文本處理中常常被忽略的那些詞,因為它們通常不承載重要的意義,也不利於搜索引擎索引和自然語言處理任務。這些詞包括助詞、介詞、連詞等,如 "the"、"is"、"at"、"which" 和 "on" 等。
stop words 越多可能代表越多冗詞贅字。
stops = stopwords.words("english")
num_stopwords_train = train['text'].apply(lambda x: len(set(x.split()) & set(stops)))
ratio_stopwords_train = num_stopwords_train / num_words_train
feature_plots(x = ratio_stopwords_train, name = "Ratio of stopwords")
🔎 Finding: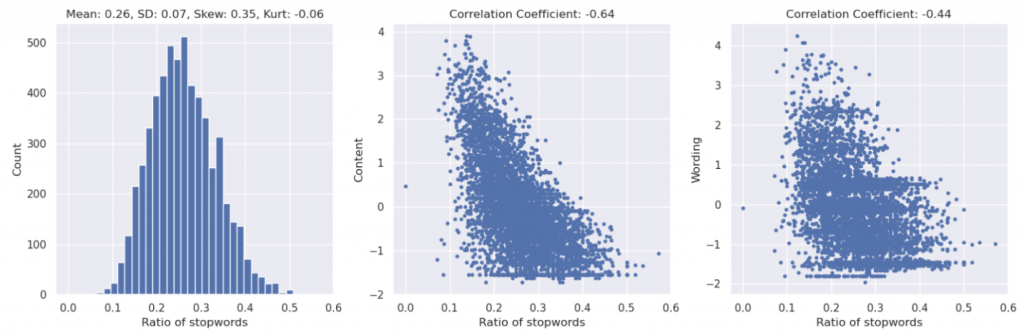
看起來還好,中度負相關。
其他還可以探討譬如說,頻繁使用名詞、動詞、形容詞的摘要,會不會是比較認真寫得高分摘要呢?這部分的討論大家有興趣的話,可以移步2的notebook看看!
或者可以計算摘要和原文的 rougeL score 或是計算摘要和原文的 Levenshtein Distance,說不定重疊的越多代表摘要改寫的越少,分數會越低?或是計算他們的相似度,相似度越高 content 分數會越高嗎?還有其他 feature 與 content/wording score 相關性的分析,我們明天會繼續討論。
❓❓除了上面提到的這些,你還能想到哪些有趣的問題呢❓❓
明天進階版本的 EDA,還會討論一些有點 tricky 的 feature,例如:把 content score rotate 30 度會發生什麼事情?(別鬧了,誰會想得到要這樣做啦!)。另外,在 [Day2] 曾經使用過的 Levenshtein Distance ,這次又要幫助我們發現一些有趣的事實了!
說不定挖掘到好的 feature 後,直接用這些 feature 訓練一個 LGBM, XGBOOST 之類 tree-based 的方法分數就超高了!根本不需要上 deberta 這種參數多訓練又慢的模型。
這邊先挖個坑,我們之後會再慢慢討論~LGBM至今仍然是kaggle競賽上被大量使用的技術喔,千萬別小看了它!嗯!👊👊
我們明天見!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵唷!
如果有任何回饋和建議,歡迎在留言區和我說✨✨
(Kaggle - CommonLit - Evaluate Student Summaries 解法分享系列)

 iThome鐵人賽
iThome鐵人賽